
La clasificación de péptidos es una tarea fundamental en bioinformática y biología computacional, que busca categorizar estas cadenas cortas de aminoácidos según sus propiedades, funciones o estructuras. Los péptidos desempeñan roles cruciales en procesos biológicos, como la señalización celular, la respuesta inmune y la regulación metabólica, por lo que su clasificación permite entender mejor su comportamiento y potenciales aplicaciones en medicina, farmacología y biotecnología. Para abordar este desafío, se emplean técnicas de ciencia de datos y machine learning, como modelos de clasificación supervisada, que utilizan características derivadas de secuencias aminoacídicas, estructuras tridimensionales o propiedades fisicoquímicas.
Objetivo
El objetivo de la clasificación entre 0 y 1 es asignar una etiqueta binaria (0 o 1) a cada instancia de un conjunto de datos, basándose en sus características. Esto permite distinguir entre dos clases o categorías, como péptidos activos vs. no activos, o cualquier otra dicotomía relevante, con el fin de predecir su comportamiento o propiedad específica.
Metodologia
CRISP-DM
Datos utilizados
El conjunto de datos recopilado se corresponde muestras de laboratorio.
- Muestras de entrenamiento: 12 402 (70%)
- Muestras de prueba: 3 545 (20%)
- Muestras de validación: 1 771 (10%)
Visualización de datos
El retiro de valores atípicos es un paso crucial en el preprocesamiento de datos para mejorar la calidad de los modelos predictivos. En este estudio, se utilizó Isolation Forest, un algoritmo eficiente para detectar anomalías, con el fin de identificar y eliminar observaciones atípicas en el conjunto de datos. Posteriormente, se optimizaron los hiperparámetros del modelo Random Forest mediante Optuna, una herramienta de optimización bayesiana que permite encontrar la mejor combinación de parámetros de manera automatizada. Se realizaron 100 experimentos para evaluar diferentes configuraciones, ajustando parámetros como el número de árboles, la profundidad máxima y el criterio de división. Este enfoque permitió no solo mejorar la precisión del modelo, sino también garantizar su robustez y generalización, demostrando la importancia de combinar técnicas avanzadas de preprocesamiento y optimización en proyectos de ciencia de datos.
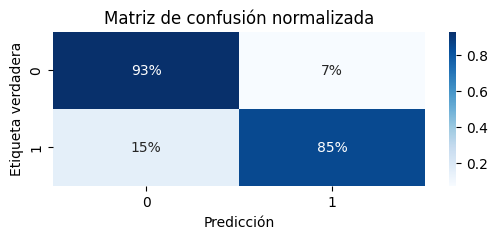
Aquí se presenta la matriz de confusión obtenida tras aplicar la optimización de hiperparámetros a las muestras de validación, la cual refleja el desempeño del modelo en términos de verdaderos positivos, falsos positivos, verdaderos negativos y falsos negativos. Esta matriz permite visualizar la capacidad del modelo para clasificar correctamente las instancias en cada categoría. Para un análisis más detallado, otras métricas de evaluación sobre los demas conjuntos de muestras, se encuentran implementadas y disponibles en el código adjunto, proporcionando una visión completa del rendimiento del modelo.
Resultados
Los resultados obtenidos indican que el modelo optimizado con Optuna presenta el mejor rendimiento en términos menor cantidad de arboles. Sin embargo, se observó una mayor dificultad en la clasificación precisa de la categoria 1 peptidos activos.
Sugerencias
Realizar un nuevo diseño de experimento. Aumentar las muestras, ya que estos modelos pueden ser potencializados con mayores y mejores muestras.
Adicionales
- Link a repositorio: Github