
La felicidad es un concepto subjetivo que abarca diversos aspectos de la vida, como la satisfacción personal, el bienestar emocional y la calidad de las relaciones interpersonales. En el caso de las madres solteras, este tema adquiere una relevancia especial debido a los desafíos únicos que enfrentan, como la responsabilidad de criar a sus hijos en solitario, equilibrar trabajo y familia, y manejar factores económicos y sociales que pueden influir en su bienestar general. Este proyecto tiene como objetivo explorar y analizar los factores que contribuyen a la felicidad de las madres solteras, utilizando técnicas de ciencia de datos para identificar patrones, correlaciones y posibles intervenciones que promuevan su bienestar.
Objetivo
Identificar los principales factores que influyen en la percepción de felicidad de madres solteras, con el fin de ofrecer recomendaciones basadas en datos para mejorar su calidad de vida.
Metodologia
CRISP-DM
Datos utilizados
Este conjunto de datos se obtuvo a partir de las respuestas de la encuesta de calidad de vida.
DANE: Microdatos
Tablas empleadas
- Características y composición del hogar
- Datos de la vivienda
- Servicios del hogar
Visualización de datos
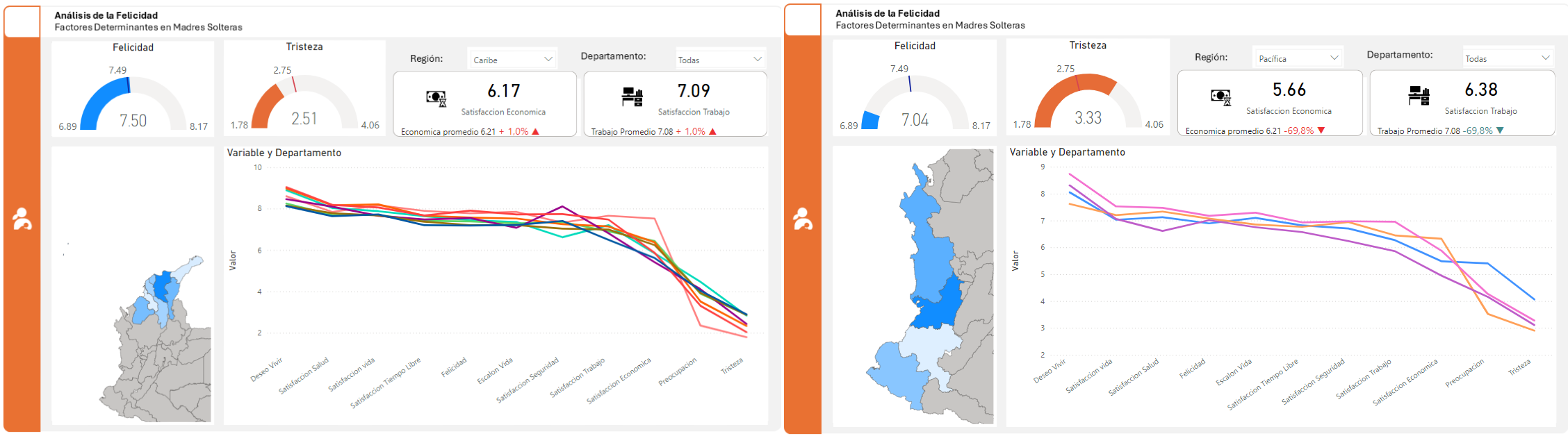
El análisis revela una marcada diferencia entre las regiones Caribe y Pacífica en cuanto a indicadores de bienestar emocional. La región Caribe se destaca por sus altos niveles de felicidad, mientras que la región Pacífica presenta los índices más bajos de felicidad y los más altos de tristeza.
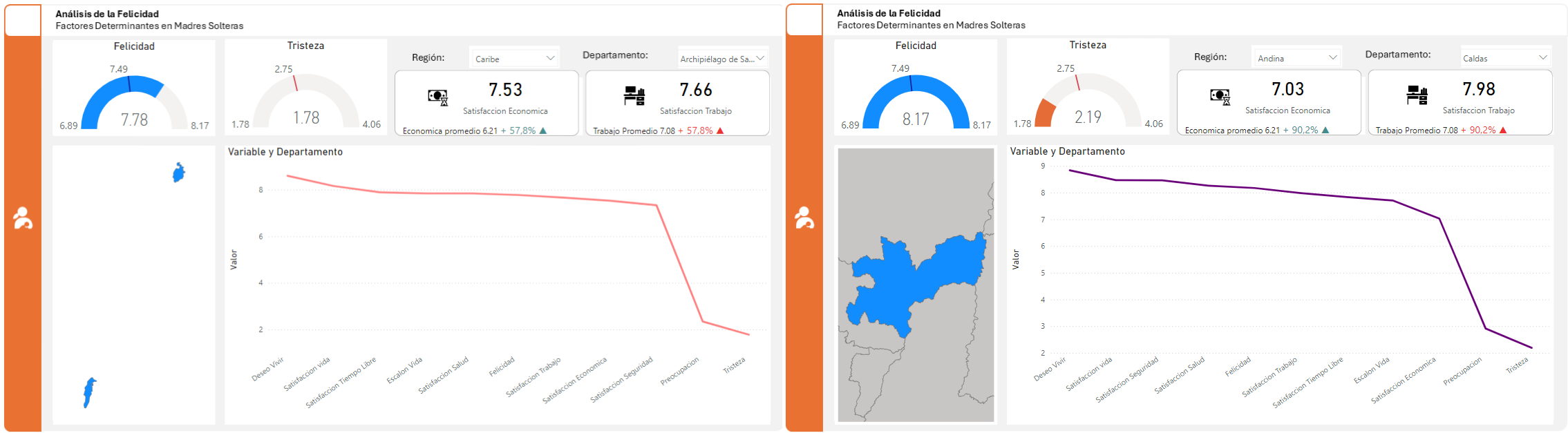
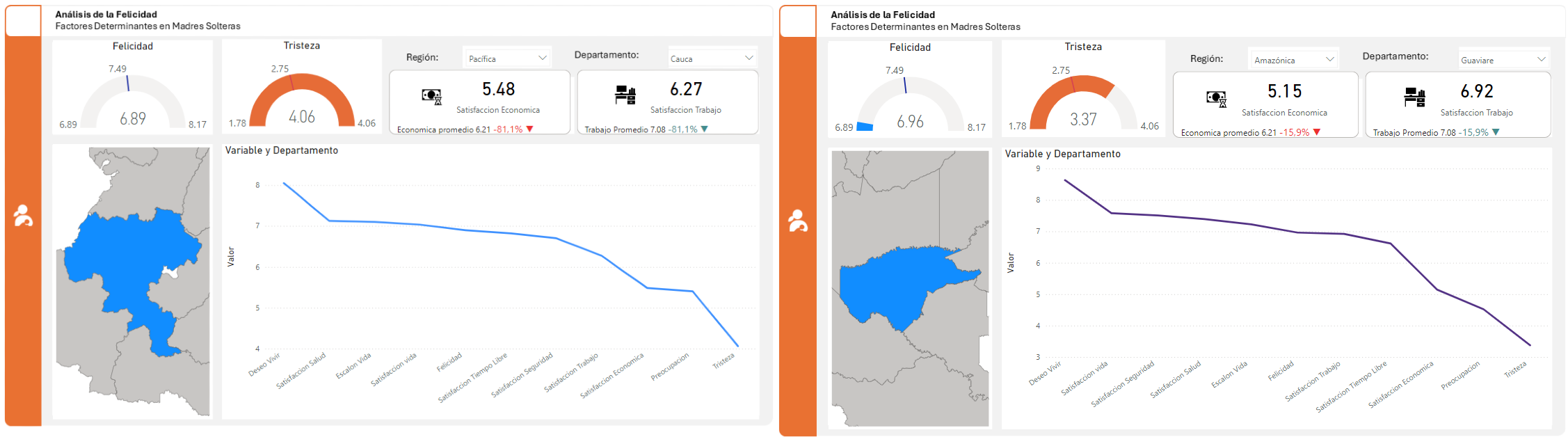
El estudio revela un marcado contraste entre los departamentos de San Andrés y Caldas, por un lado, y Cauca y Guaviare, por otro. Los primeros se caracterizan por altos niveles de felicidad y bajos índices de tristeza, mientras que los segundos presentan la situación inversa.
Recomendaciones
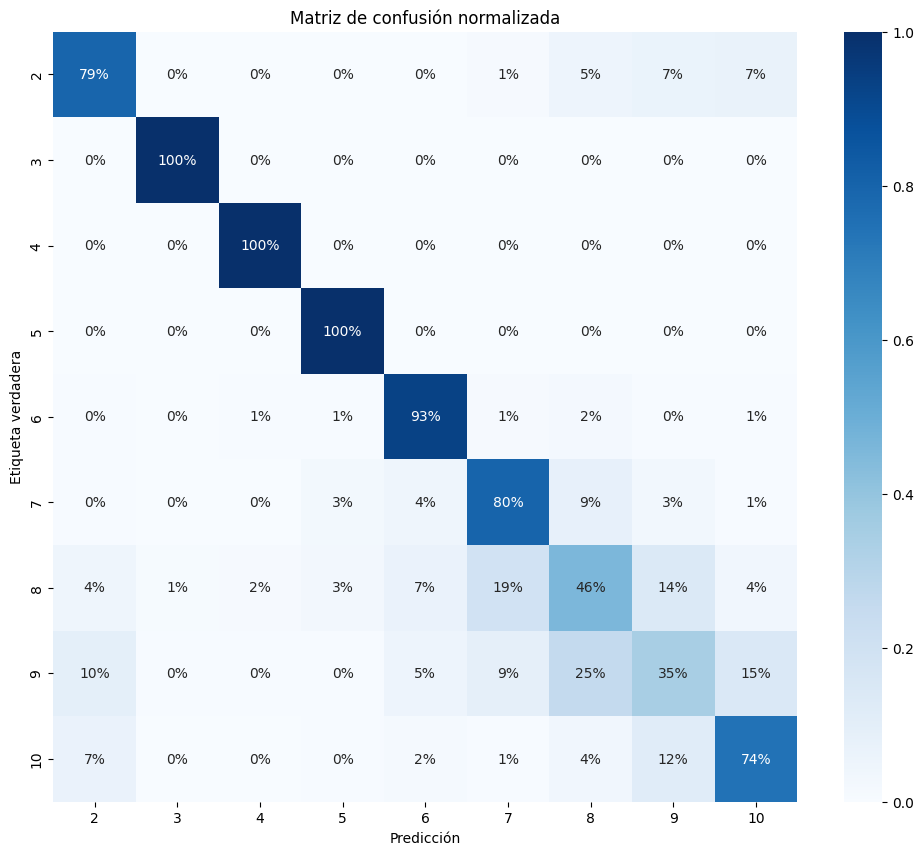
Aunque el modelo de clasificación optimizado con Optuna muestra un buen desempeño general, se observa una disminución en su precisión al clasificar los niveles más altos de felicidad. Los resultados sugieren que dividir el conjunto de datos en dos grupos (felicidad mayor o menor a 8) podría mejorar significativamente la capacidad del modelo para distinguir entre los niveles superiores.
Se construyó una base de datos familiar, incluyendo relaciones entre familiares directos y ampliados. Debido a la falta de datos, se omitió la inclusión de mascotas. Se realizó una cuidadosa distinción entre conceptos de familia y parentesco, y se enriqueció la información de cada individuo al agregar múltiples relaciones. Además, se identificaron y corrigieron las familias con información incompleta
Dashboard
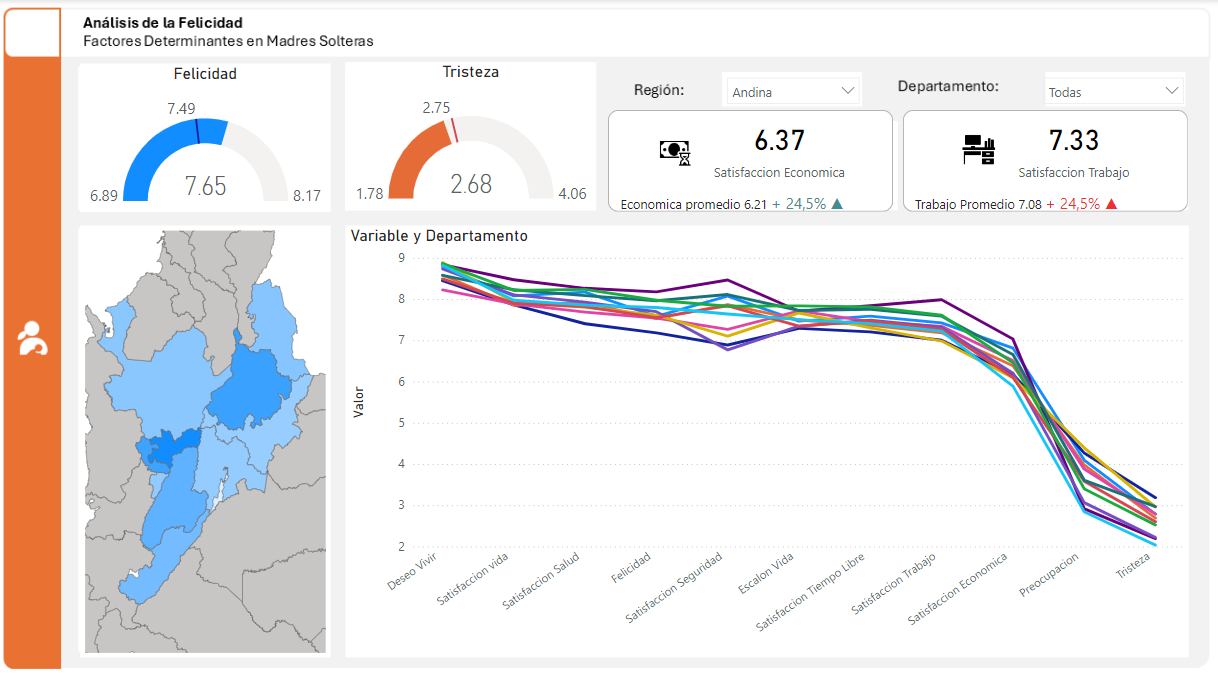
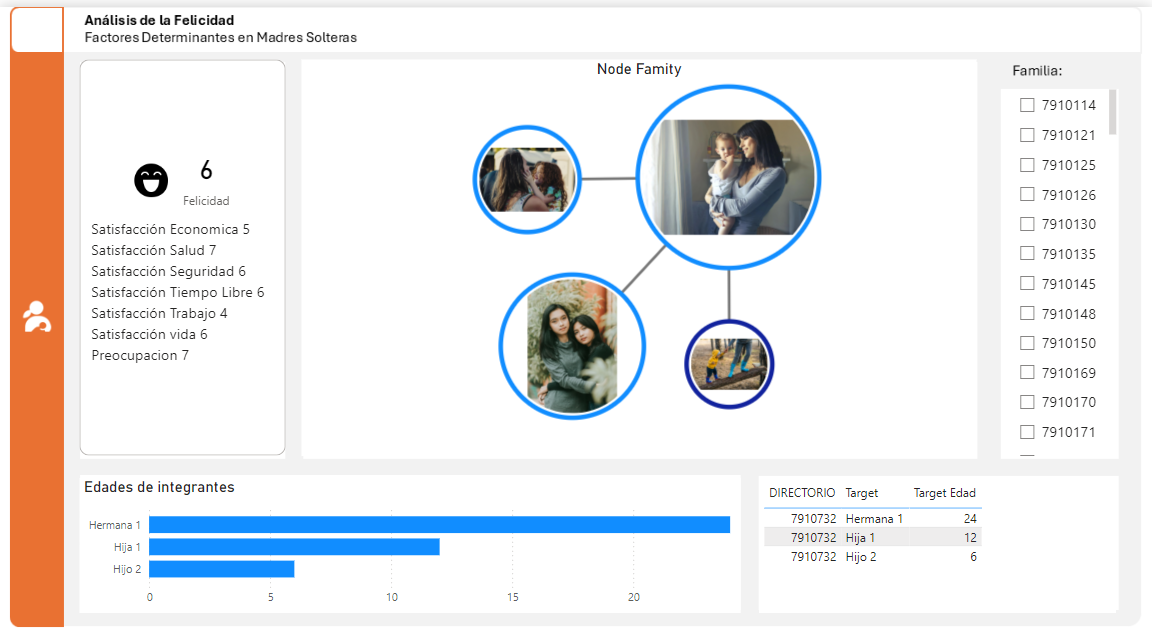
Adicionales
- Link a repositorio: Github
- Link a Power BI: Dashboard
- Aplicación shiny-R: Aplicación